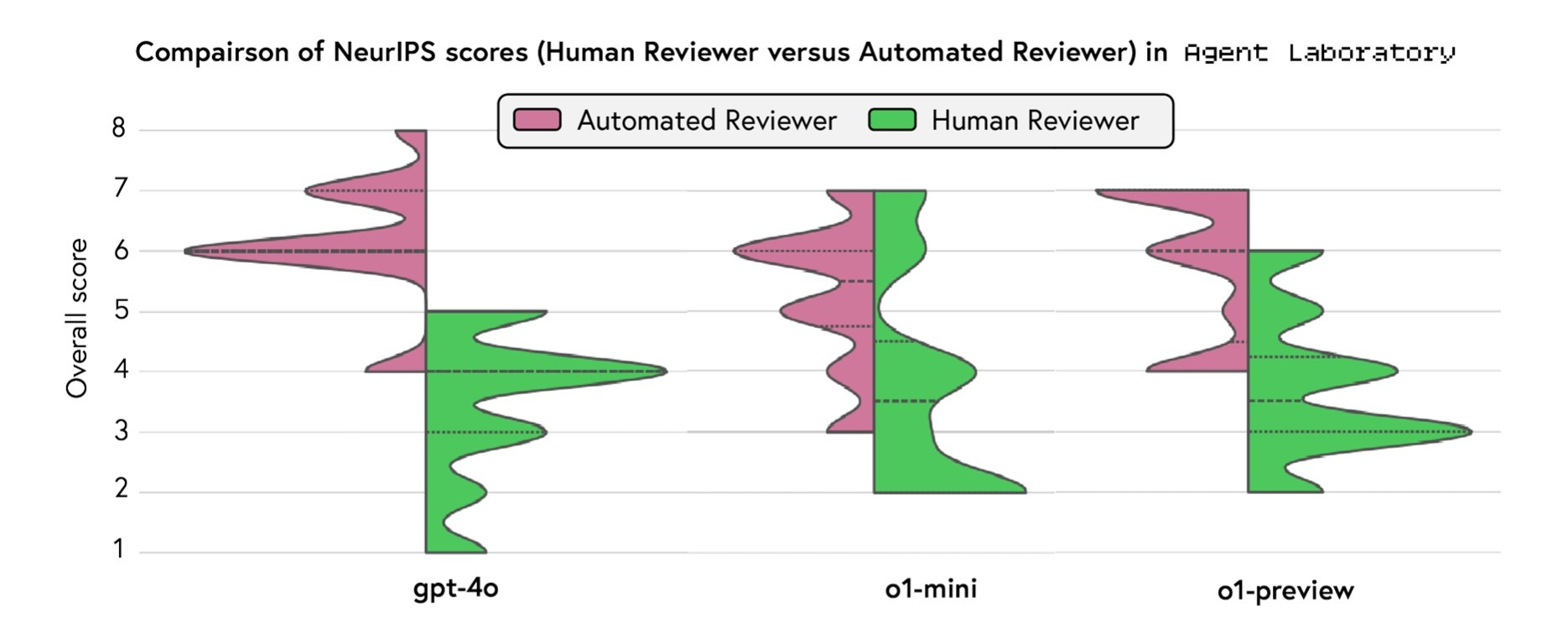
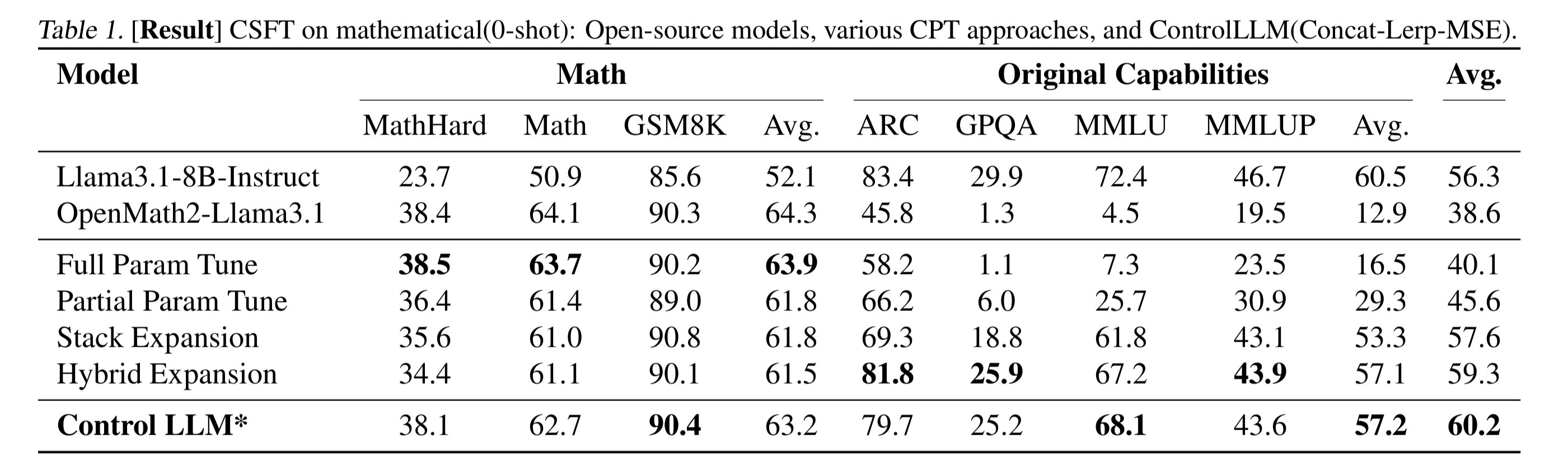
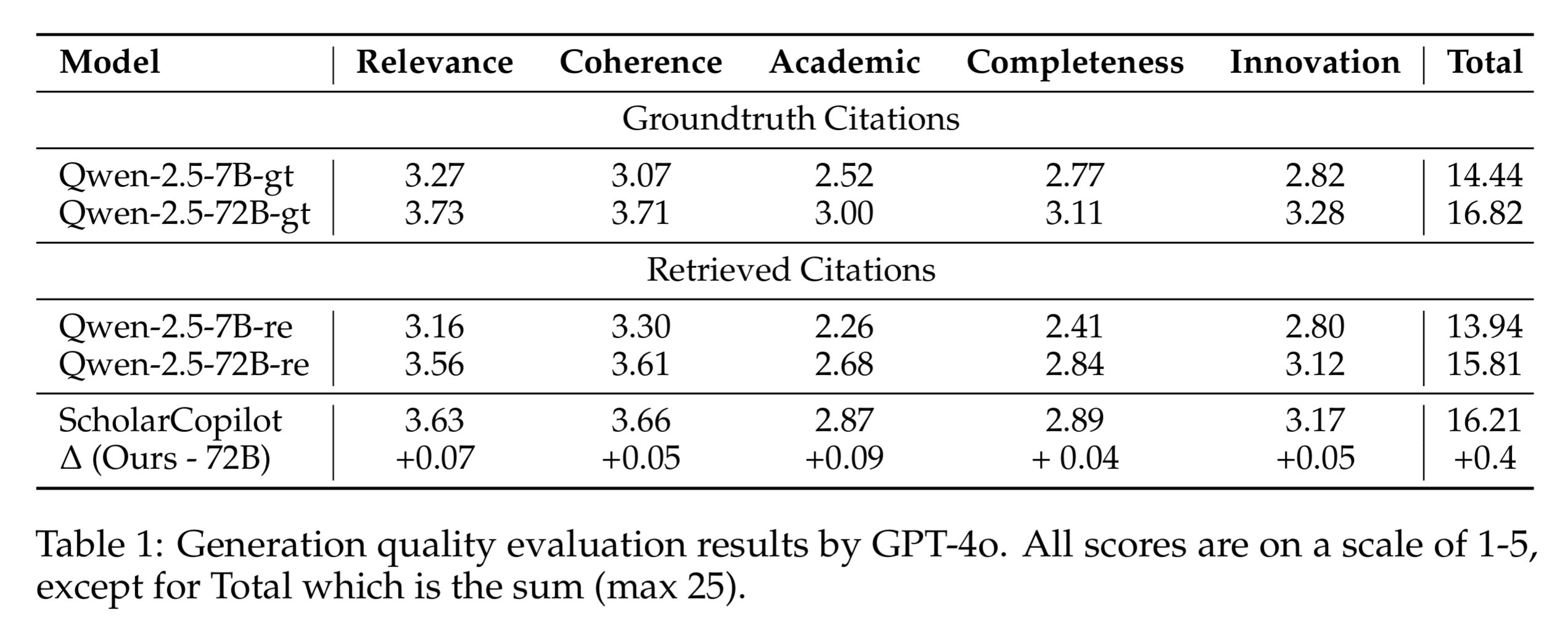
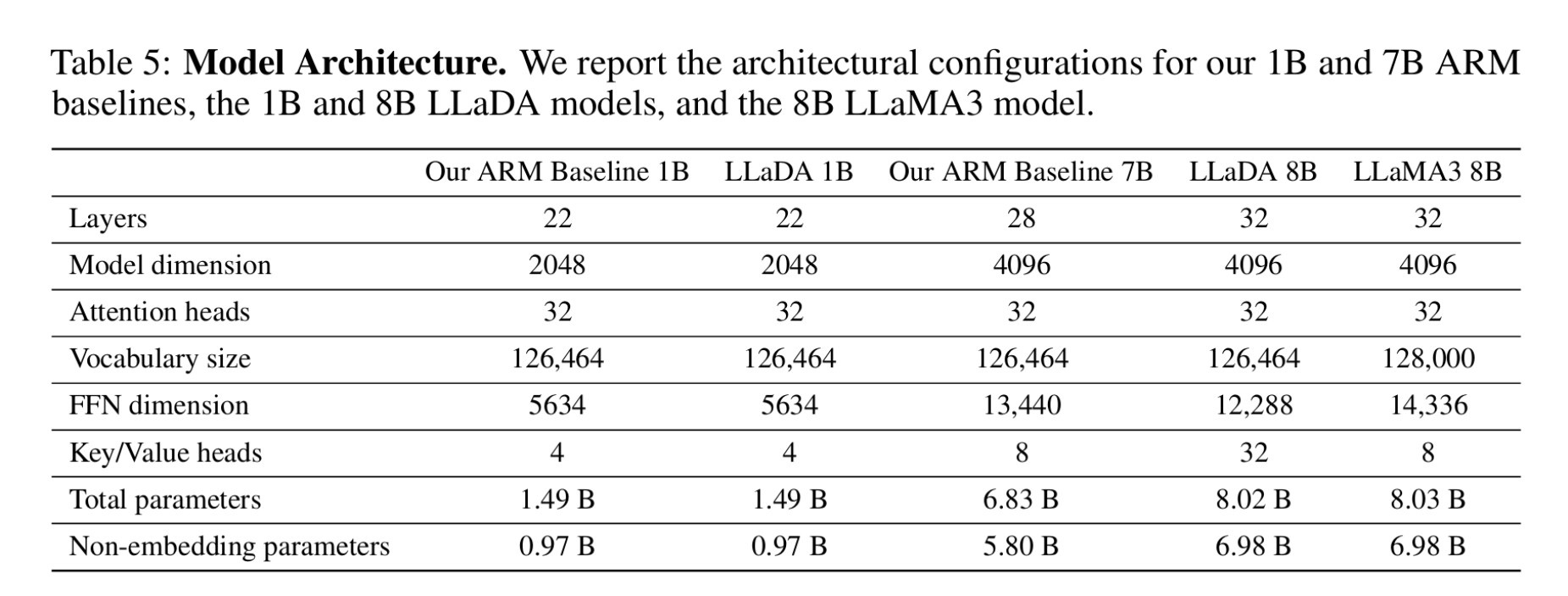
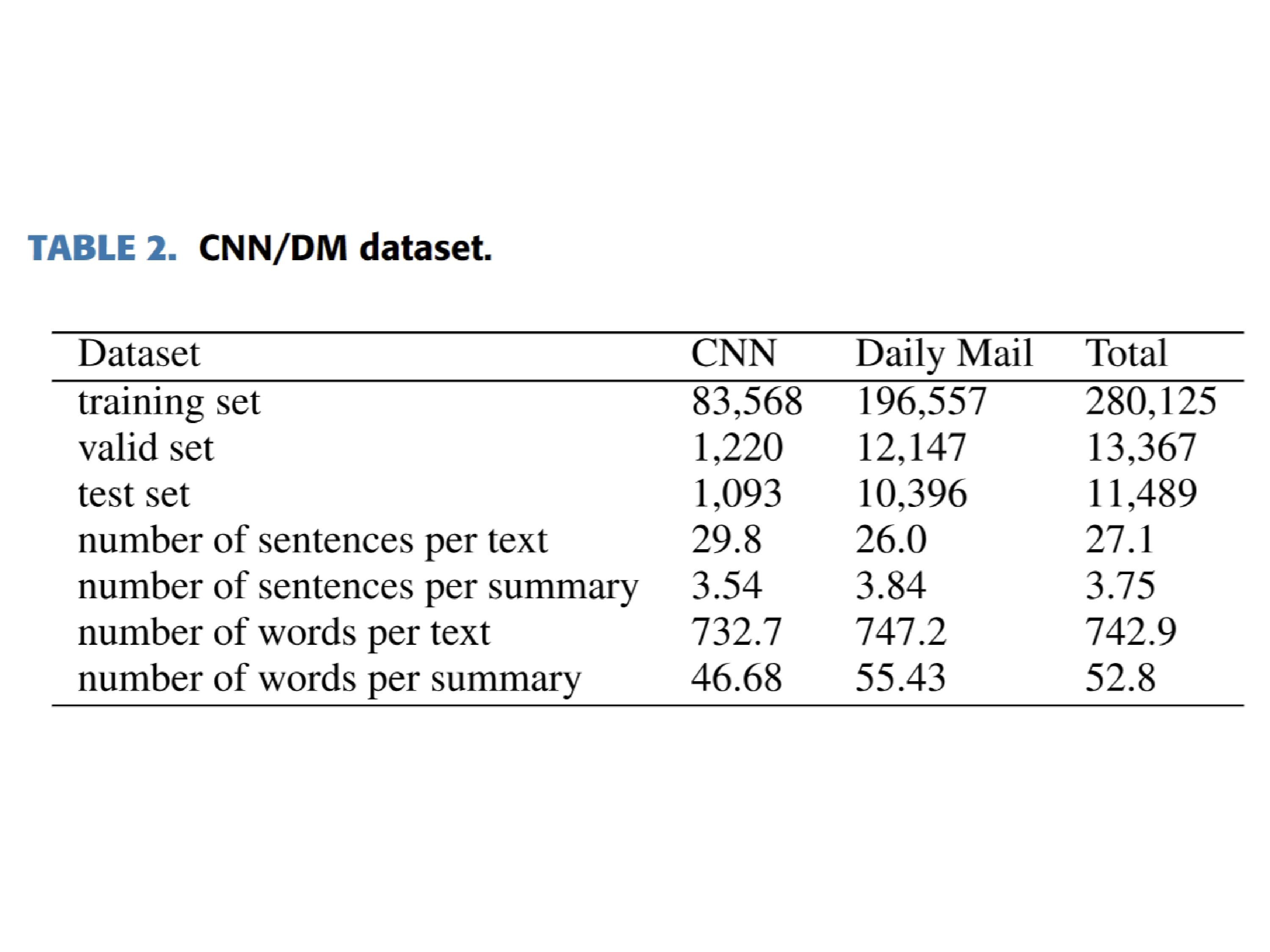
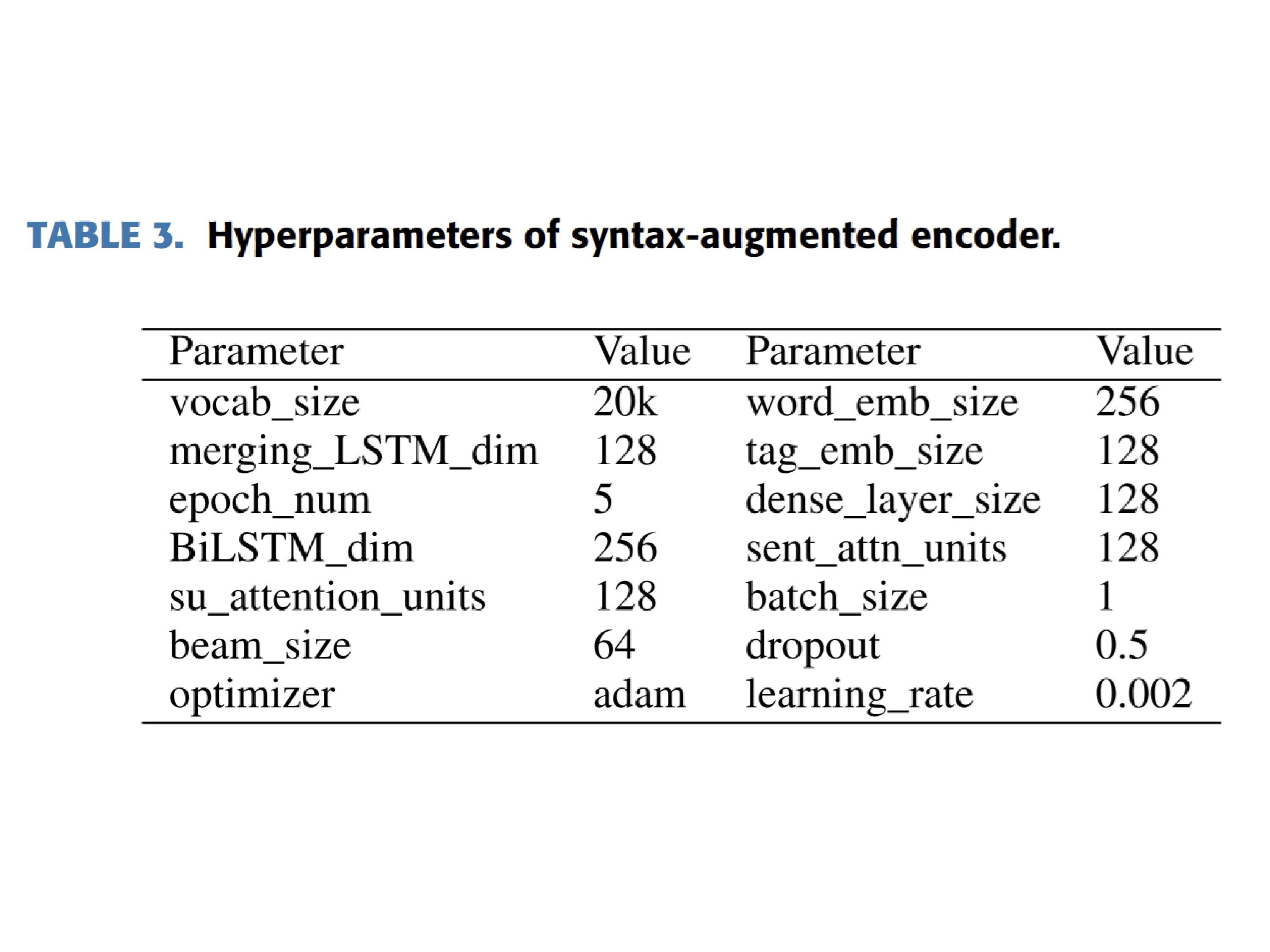
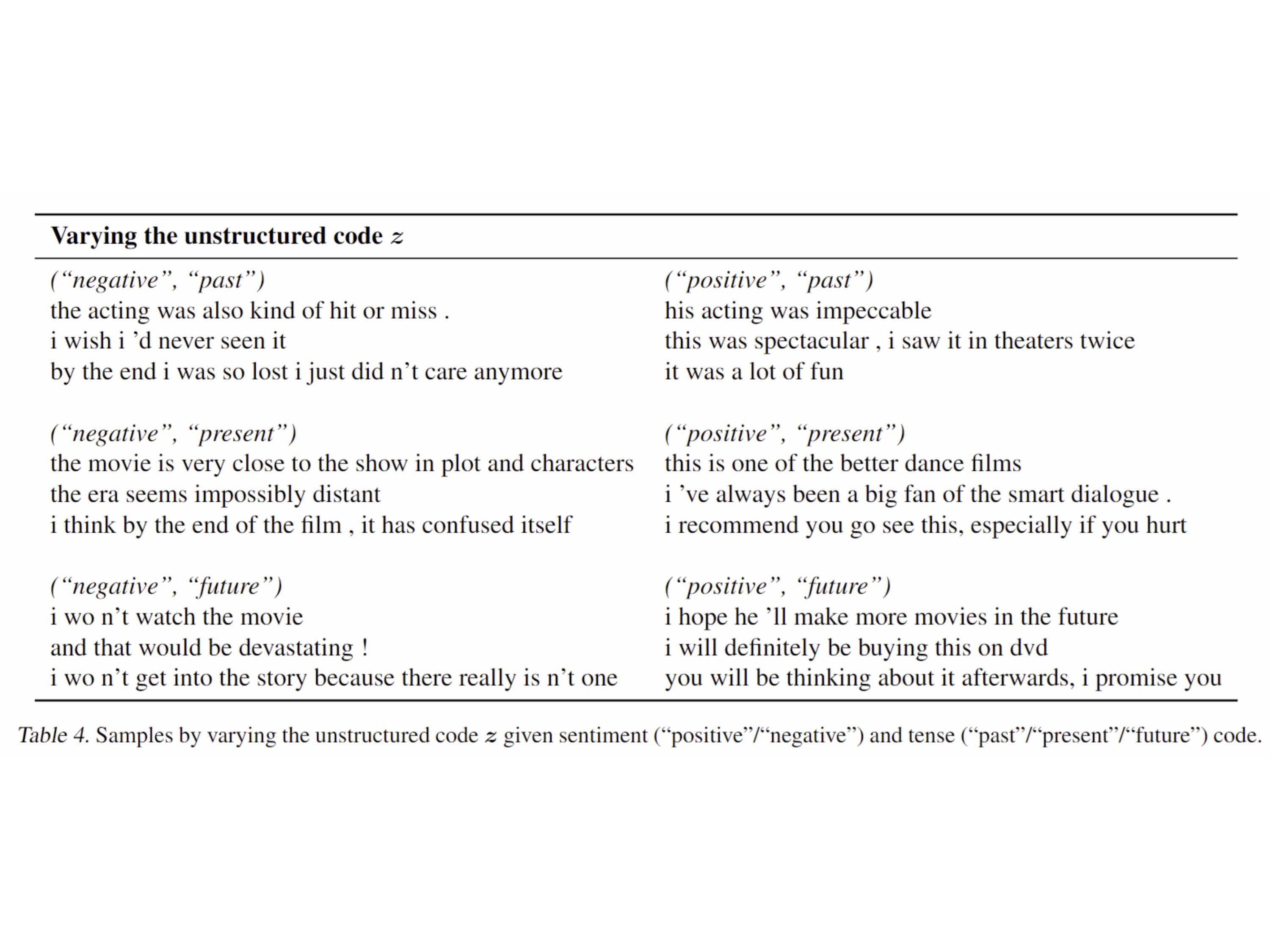
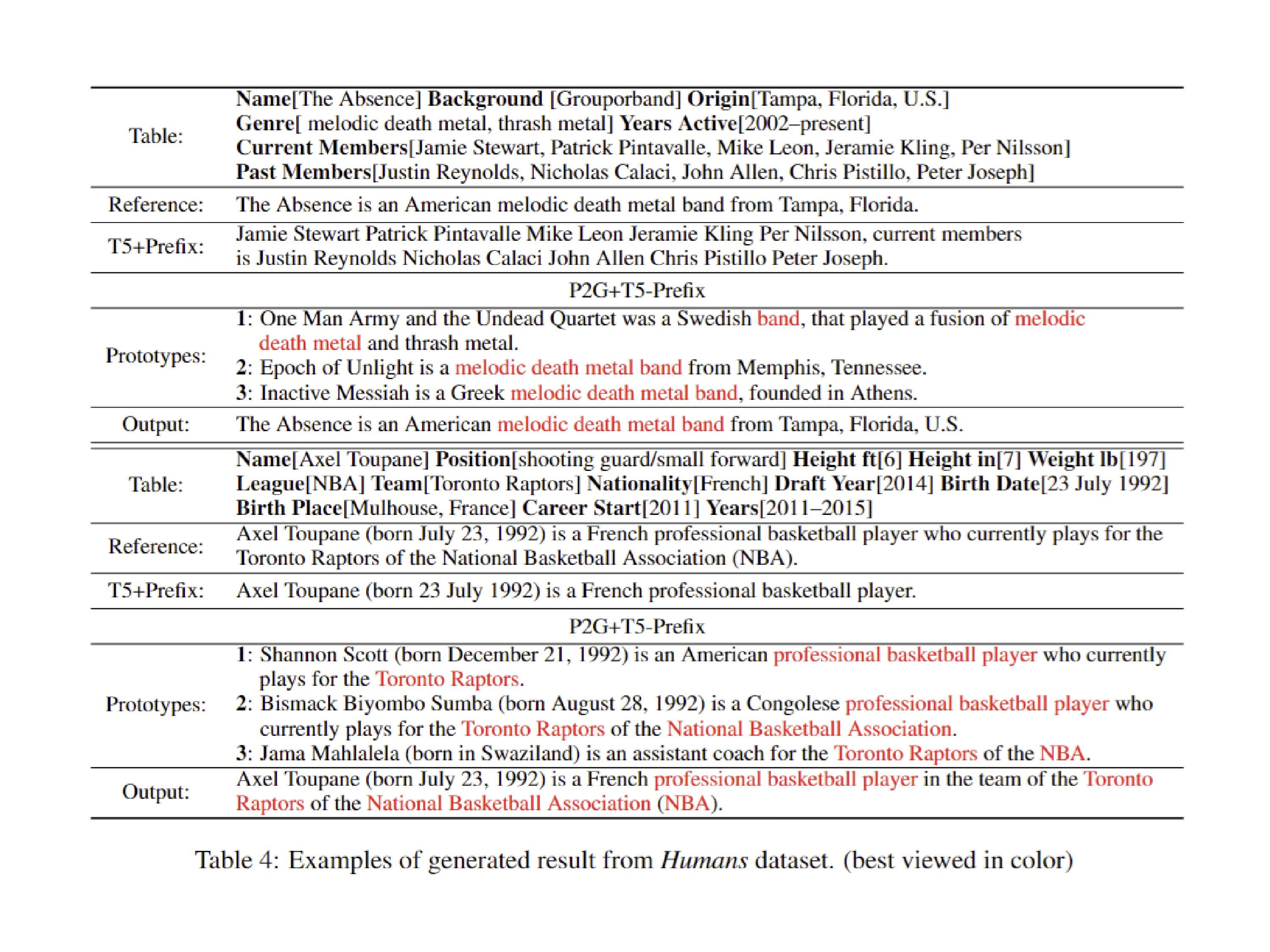
AX-b task is a task designed to evaluate a model’s ability to perform logical reasoning and generalization. It involves making logical deductions based on given premises.
Evaluate a model’s understanding of various linguistic phenomena.
Source
Our implementation is based on the SuperGLUE dataset, a benchmark designed to evaluate the performance of natural language understanding models on diverse tasks.
For the most up-to-date information on the SuperGLUE dataset, you can visit the official website: SuperGLUE
Dataset and Source Code
You can download the dataset and source code using the following links:
Download the Dataset: Use the provided link to download the dataset.
Access Colab Notebook: Open the Colab notebook using the provided link. Make sure you have a Google account to access Colab.
Upload Dataset to Colab: If the dataset is not already included in the Colab environment, upload it using the appropriate commands.
Run Code Cells: Execute each code cell in the Colab notebook to go through the implementation steps.
Review Results: Check the output of the code cells to see the results of the task on the provided dataset.
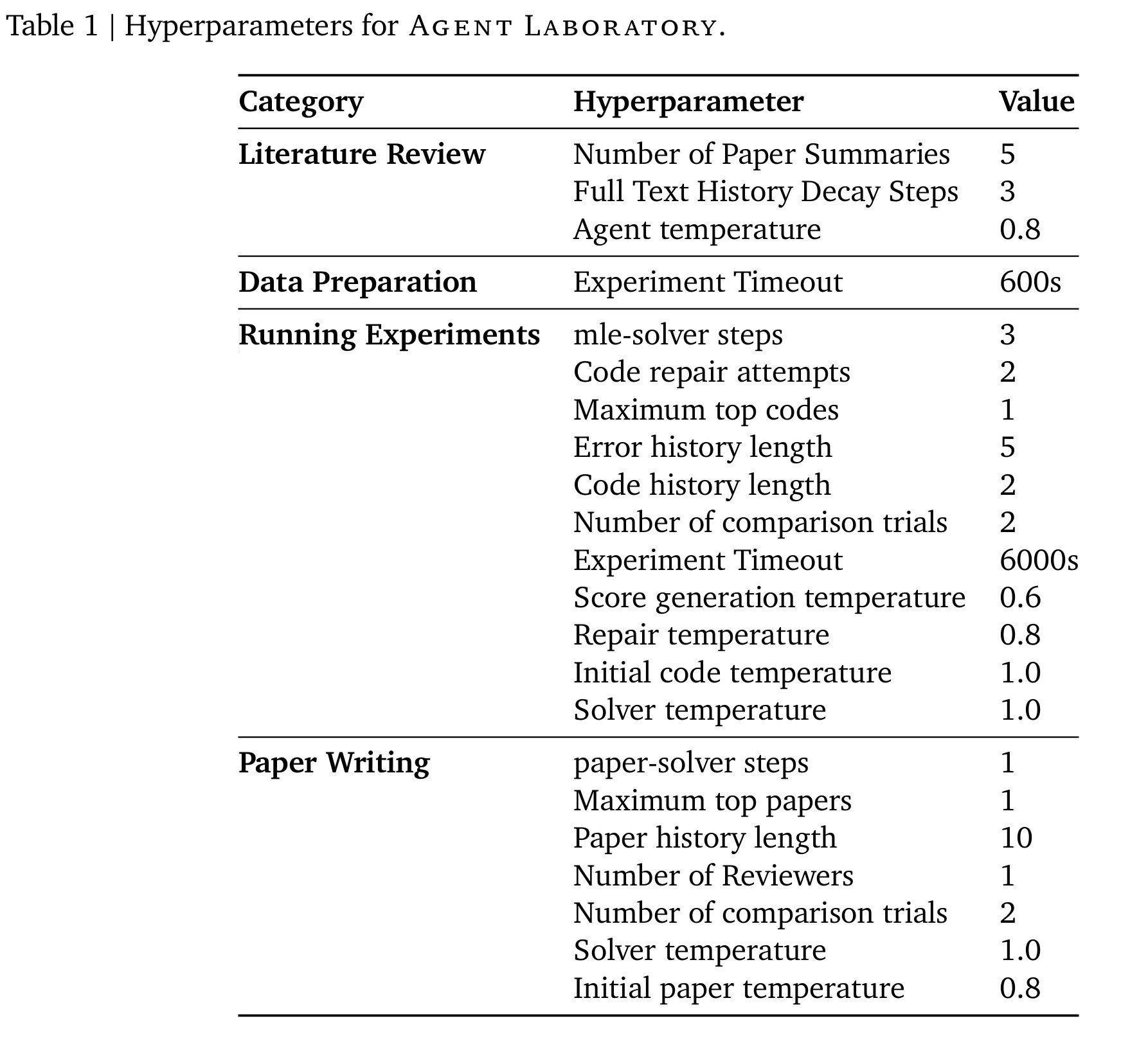
Performance
This is a performance comparison table with state-of-the-art (SOTA) models.
The performance was measured using validation data, not a public benchmark test dataset. There may be slight differences in performance.
Model
Accuracy
Mattew’s Corr
ST-MoE-32B
-
72.3
PaLM 540B
-
72.9
Turing NLR v5
-
67.8
Ours (Educational purpose, training-based)
0.59
0.0
Ours (Educational purpose, llm-based)
0.40
0.0
Feel free to reach out if you encounter any issues or have questions regarding the implementation.
AX-b Task Implementation (Training-based)
Overview
AX-b task is a task designed to evaluate a model’s ability to perform logical reasoning and generalization. It involves making logical deductions based on given premises.
Evaluate a model’s understanding of various linguistic phenomena.
Source
Our implementation is based on the SuperGLUE dataset, a benchmark designed to evaluate the performance of natural language understanding models on diverse tasks.
For the most up-to-date information on the SuperGLUE dataset, you can visit the official website: SuperGLUE
Download Dataset and Source Code
You can download the dataset and source code using the following links:
Download the Dataset: Use the provided link to download the dataset.
Access Colab Notebook: Open the Colab notebook using the provided link. Make sure you have a Google account to access Colab.
Upload Dataset to Colab: If the dataset is not already included in the Colab environment, upload it using the appropriate commands.
Run Code Cells: Execute each code cell in the Colab notebook to go through the implementation steps.
Review Results: Check the output of the code cells to see the results of the task on the provided dataset.
Performance
This is a performance comparison table with state-of-the-art (SOTA) models.
The performance was evaluated using internally split data, not a public benchmark test dataset. There may be slight differences in performance.
Model
Accuracy
Mattew’s Corr
ST-MoE-32B
-
72.3
PaLM 540B
-
72.9
Turing NLR v5
-
67.8
Ours (Educational purpose, training-based)
0.59
0.0
Ours (Educational purpose, llm-based)
0.40
0.0
Feel free to reach out if you encounter any issues or have questions regarding the implementation.
BoolQ Task Implementation (LLM-based)
Overview
BoolQ (Boolean Questions) consists of yes/no questions about short passages from Google search results, requiring understanding of text content to answer.
Source
Our implementation is based on the SuperGLUE dataset, a benchmark designed to evaluate the performance of natural language understanding models on diverse tasks.
For the most up-to-date information on the SuperGLUE dataset, you can visit the official website: SuperGLUE
Dataset and Source Code
You can download the dataset and source code using the following links:
Download the Dataset: Use the provided link to download the dataset.
Access Colab Notebook: Open the Colab notebook using the provided link. Make sure you have a Google account to access Colab.
Upload Dataset to Colab: If the dataset is not already included in the Colab environment, upload it using the appropriate commands.
Run Code Cells: Execute each code cell in the Colab notebook to go through the implementation steps.
Review Results: Check the output of the code cells to see the results of the task on the provided dataset.
Performance
This is a performance comparison table with state-of-the-art (SOTA) models.
The performance was measured using validation data, not a public benchmark test dataset. There may be slight differences in performance.
Model
Accuracy
F1
ST-MoE-32B
92.4
-
Turing NLR v5
92.0
-
Vega v2
90.5
-
Ours (Educational purpose, trining-based)
72.8
72.8
Ours (Educational purpose, llm-based)
86.14
86.14
Feel free to reach out if you encounter any issues or have questions regarding the implementation.
BoolQ Task Implementation (Training-based)
Overview
BoolQ (Boolean Questions) consists of yes/no questions about short passages from Google search results, requiring understanding of text content to answer.
Source
Our implementation is based on the SuperGLUE dataset, a benchmark designed to evaluate the performance of natural language understanding models on diverse tasks.
For the most up-to-date information on the SuperGLUE dataset, you can visit the official website: SuperGLUE
Dataset and Source Code
You can download the dataset and source code using the following links:
Download the Dataset: Use the provided link to download the dataset.
Access Colab Notebook: Open the Colab notebook using the provided link. Make sure you have a Google account to access Colab.
Upload Dataset to Colab: If the dataset is not already included in the Colab environment, upload it using the appropriate commands.
Run Code Cells: Execute each code cell in the Colab notebook to go through the implementation steps.
Review Results: Check the output of the code cells to see the results of the task on the provided dataset.
Performance
This is a performance comparison table with state-of-the-art (SOTA) models.
The performance was measured using validation data, not a public benchmark test dataset. There may be slight differences in performance.
Model
Accuracy
F1
ST-MoE-32B
92.4
-
Turing NLR v5
92.0
-
Vega v2
90.5
-
Ours (Educational purpose, trining-based)
72.8
72.8
Ours (Educational purpose, llm-based)
86.14
86.14
Feel free to reach out if you encounter any issues or have questions regarding the implementation.
CB Task Implementation (LLM-based)
Overview
CB (CommitmentBank) is a sentiment-annotated task from real conversations, labeled as [entailment, neutral, contradiction].
Source
Our implementation is based on the SuperGLUE dataset, a benchmark designed to evaluate the performance of natural language understanding models on diverse tasks.
For the most up-to-date information on the SuperGLUE dataset, you can visit the official website: SuperGLUE
Dataset and Source Code
You can download the dataset and source code using the following links:
Download the Dataset: Use the provided link to download the dataset.
Access Colab Notebook: Open the Colab notebook using the provided link. Make sure you have a Google account to access Colab.
Upload Dataset to Colab: If the dataset is not already included in the Colab environment, upload it using the appropriate commands.
Run Code Cells: Execute each code cell in the Colab notebook to go through the implementation steps.
Review Results: Check the output of the code cells to see the results of the task on the provided dataset.
Performance
This is a performance comparison table with state-of-the-art (SOTA) models.
The performance was measured using validation data, not a public benchmark test dataset. There may be slight differences in performance.
Model
Accuracy
F1
ST-MoE-32B
99.2
98.6
ERNIE 3.0
99.2
98.6
Turing NLR v5
98.0
96.9
Ours (Educational purpose, trining-based)
82.1
82.1
Ours (Educational purpose, llm-based)
71.4
71.4
Feel free to reach out if you encounter any issues or have questions regarding the implementation.
CB Task Implementation (Training-based)
Overview
CB (CommitmentBank) is a sentiment-annotated task from real conversations, labeled as [entailment, neutral, contradiction].
Source
Our implementation is based on the SuperGLUE dataset, a benchmark designed to evaluate the performance of natural language understanding models on diverse tasks.
For the most up-to-date information on the SuperGLUE dataset, you can visit the official website: SuperGLUE
Dataset and Source Code
You can download the dataset and source code using the following links:
Download the Dataset: Use the provided link to download the dataset.
Access Colab Notebook: Open the Colab notebook using the provided link. Make sure you have a Google account to access Colab.
Upload Dataset to Colab: If the dataset is not already included in the Colab environment, upload it using the appropriate commands.
Run Code Cells: Execute each code cell in the Colab notebook to go through the implementation steps.
Review Results: Check the output of the code cells to see the results of the task on the provided dataset.
Performance
This is a performance comparison table with state-of-the-art (SOTA) models.
The performance was measured using validation data, not a public benchmark test dataset. There may be slight differences in performance.
Model
Accuracy
F1
ST-MoE-32B
99.2
98.6
ERNIE 3.0
99.2
98.6
Turing NLR v5
98.0
96.9
Ours (Educational purpose, trining-based)
82.1
82.1
Ours (Educational purpose, llm-based)
71.4
71.4
Feel free to reach out if you encounter any issues or have questions regarding the implementation.
CoNLL2003 Task Implementation (LLM-based)
Overview
The CoNLL2003 dataset consists of news articles from the Reuters Corpus and is annotated with four types of named entities: persons, locations, organizations, and miscellaneous entities.
Source
Our implementation is based on the CoNLL 2003 dataset, a benchmark designed to evaluate the performance of natural language processing models on tasks such as named entity recognition (NER).
For the most up-to-date information on the CoNLL 2003 dataset, you can refer to research articles and documentation that discuss its creation, usage, and impact on the field of natural language processing.
Dataset and Source Code
You can download the dataset and source code using the following links:
Download the Dataset: Use the provided link to download the dataset.
Access Colab Notebook: Open the Colab notebook using the provided link. Make sure you have a Google account to access Colab.
Upload Dataset to Colab: If the dataset is not already included in the Colab environment, upload it using the appropriate commands.
Run Code Cells: Execute each code cell in the Colab notebook to go through the implementation steps.
Review Results: Check the output of the code cells to see the results of the task on the provided dataset.
Performance
This is a performance comparison table with state-of-the-art (SOTA) models.
The performance was measured using validation data, not a public benchmark test dataset. There may be slight differences in performance.
Model
Accuracy
F1
ACE + document-context
94.6
-
LUKE
94.3
-
Co-regularized LUKE
94.2
-
Ours (Educational purpose, trining-based)
80.6
80.6
Ours (Educational purpose, llm-based)
35.1
35.1
Feel free to reach out if you encounter any issues or have questions regarding the implementation.
CoNLL2003 Task Implementation (Training-based)
Overview
The CoNLL2003 dataset consists of news articles from the Reuters Corpus and is annotated with four types of named entities: persons, locations, organizations, and miscellaneous entities.
Source
Our implementation is based on the CoNLL 2003 dataset, a benchmark designed to evaluate the performance of natural language processing models on tasks such as named entity recognition (NER).
For the most up-to-date information on the CoNLL 2003 dataset, you can refer to research articles and documentation that discuss its creation, usage, and impact on the field of natural language processing.
Dataset and Source Code
You can download the dataset and source code using the following links:
Download the Dataset: Use the provided link to download the dataset.
Access Colab Notebook: Open the Colab notebook using the provided link. Make sure you have a Google account to access Colab.
Upload Dataset to Colab: If the dataset is not already included in the Colab environment, upload it using the appropriate commands.
Run Code Cells: Execute each code cell in the Colab notebook to go through the implementation steps.
Review Results: Check the output of the code cells to see the results of the task on the provided dataset.
Performance
This is a performance comparison table with state-of-the-art (SOTA) models.
The performance was measured using validation data, not a public benchmark test dataset. There may be slight differences in performance.
Model
Accuracy
F1
ACE + document-context
94.6
-
LUKE
94.3
-
Co-regularized LUKE
94.2
-
Ours (Educational purpose, trining-based)
80.6
80.6
Ours (Educational purpose, llm-based)
35.1
35.1
Feel free to reach out if you encounter any issues or have questions regarding the implementation.
COPA Task Implementation (LLM-based)
Overview
COPA (Choice of Plausible Alternatives) is the task of choosing an answer for a given question, and every question has two choices.
Source
Our implementation is based on the SuperGLUE dataset, a benchmark designed to evaluate the performance of natural language understanding models on diverse tasks.
For the most up-to-date information on the SuperGLUE dataset, you can visit the official website: SuperGLUE
Dataset and Source Code
You can download the dataset and source code using the following links:
Download the Dataset: Use the provided link to download the dataset.
Access Colab Notebook: Open the Colab notebook using the provided link. Make sure you have a Google account to access Colab.
Upload Dataset to Colab: If the dataset is not already included in the Colab environment, upload it using the appropriate commands.
Run Code Cells: Execute each code cell in the Colab notebook to go through the implementation steps.
Review Results: Check the output of the code cells to see the results of the task on the provided dataset.
Performance
This is a performance comparison table with state-of-the-art (SOTA) models.
The performance was measured using validation data, not a public benchmark test dataset. There may be slight differences in performance.
Model
Accuracy
Vega v2
99.4
ST-MoE-32B
99.2
Turing NLR v5
98.2
Ours (Educational purpose, trining-based)
75.0
Ours (Educational purpose, llm-based)
89.0
Feel free to reach out if you encounter any issues or have questions regarding the implementation.
COPA Task Implementation (Training-based)
Overview
COPA (Choice of Plausible Alternatives) is the task of choosing an answer for a given question, and every question has two choices.
Source
Our implementation is based on the SuperGLUE dataset, a benchmark designed to evaluate the performance of natural language understanding models on diverse tasks.
For the most up-to-date information on the SuperGLUE dataset, you can visit the official website: SuperGLUE
Dataset and Source Code
You can download the dataset and source code using the following links:
Download the Dataset: Use the provided link to download the dataset.
Access Colab Notebook: Open the Colab notebook using the provided link. Make sure you have a Google account to access Colab.
Upload Dataset to Colab: If the dataset is not already included in the Colab environment, upload it using the appropriate commands.
Run Code Cells: Execute each code cell in the Colab notebook to go through the implementation steps.
Review Results: Check the output of the code cells to see the results of the task on the provided dataset.
Performance
This is a performance comparison table with state-of-the-art (SOTA) models.
The performance was measured using validation data, not a public benchmark test dataset. There may be slight differences in performance.
Model
Accuracy
Vega v2
99.4
ST-MoE-32B
99.2
Turing NLR v5
98.2
Ours (Educational purpose, trining-based)
75.0
Ours (Educational purpose, llm-based)
89.0
Feel free to reach out if you encounter any issues or have questions regarding the implementation.
MultiRC Task Implementation (LLM-based)
Overview
Multi-Sentence Reading Comprehension (MultiRC) is a task in NLP where the goal is to identify correct answers to questions about a paragraph.
Source
Our implementation is based on the SuperGLUE dataset, a benchmark designed to evaluate the performance of natural language understanding models on diverse tasks.
For the most up-to-date information on the SuperGLUE dataset, you can visit the official website: SuperGLUE
Dataset and Source Code
You can download the dataset and source code using the following links:
Download the Dataset: Use the provided link to download the dataset.
Access Colab Notebook: Open the Colab notebook using the provided link. Make sure you have a Google account to access Colab.
Upload Dataset to Colab: If the dataset is not already included in the Colab environment, upload it using the appropriate commands.
Run Code Cells: Execute each code cell in the Colab notebook to go through the implementation steps.
Review Results: Check the output of the code cells to see the results of the task on the provided dataset.
Performance
This is a performance comparison table with state-of-the-art (SOTA) models.
The performance was measured using validation data, not a public benchmark test dataset. There may be slight differences in performance.
Model
F1
Exact Match
PaLM 540B
90.1
69.2
DeBERTa-1.5B
88.2
63.7
T5-11B
88.1
63.3
Ours (Educatinal purpose, training-based)
89.6
28.1
Ours (Educational purpose, llm-based)
72.0
24.6
Feel free to reach out if you encounter any issues or have questions regarding the implementation.
MultiRC Task Implementation (Training-based)
Overview
Multi-Sentence Reading Comprehension (MultiRC) is a task in NLP where the goal is to identify correct answers to questions about a paragraph.
Source
Our implementation is based on the SuperGLUE dataset, a benchmark designed to evaluate the performance of natural language understanding models on diverse tasks.
For the most up-to-date information on the SuperGLUE dataset, you can visit the official website: SuperGLUE
Dataset and Source Code
You can download the dataset and source code using the following links:
Download the Dataset: Use the provided link to download the dataset.
Access Colab Notebook: Open the Colab notebook using the provided link. Make sure you have a Google account to access Colab.
Upload Dataset to Colab: If the dataset is not already included in the Colab environment, upload it using the appropriate commands.
Run Code Cells: Execute each code cell in the Colab notebook to go through the implementation steps.
Review Results: Check the output of the code cells to see the results of the task on the provided dataset.
Performance
This is a performance comparison table with state-of-the-art (SOTA) models.
The performance was measured using validation data, not a public benchmark test dataset. There may be slight differences in performance.
Model
F1
Exact Match
PaLM 540B
90.1
69.2
DeBERTa-1.5B
88.2
63.7
T5-11B
88.1
63.3
Ours (Educatinal purpose, training-based)
89.6
28.1
Ours (Educational purpose, llm-based)
72.0
24.6
Feel free to reach out if you encounter any issues or have questions regarding the implementation.
RTE Task Implementation (LLM-based)
Overview
Recognizing Textual Entailment (RTE) is a task in NLP where the goal is to determine whether one piece of text (the hypothesis) can be inferred or logically deduced from another piece of text (the premise). In other words, given a premise sentence and a hypothesis sentence, the model needs to determine whether the premise entails, contradicts, or is neutral with respect to the hypothesis.
Source
Our implementation is based on the SuperGLUE dataset, a benchmark designed to evaluate the performance of natural language understanding models on diverse tasks.
For the most up-to-date information on the SuperGLUE dataset, you can visit the official website: SuperGLUE
Dataset and Source Code
You can download the dataset and source code using the following links:
Download the Dataset: Use the provided link to download the dataset.
Access Colab Notebook: Open the Colab notebook using the provided link. Make sure you have a Google account to access Colab.
Upload Dataset to Colab: If the dataset is not already included in the Colab environment, upload it using the appropriate commands.
Run Code Cells: Execute each code cell in the Colab notebook to go through the implementation steps.
Review Results: Check the output of the code cells to see the results of the task on the provided dataset.
Performance
This is a performance comparison table with state-of-the-art (SOTA) models.
The performance was measured using validation data, not a public benchmark test dataset. There may be slight differences in performance.
Model
Accuracy
F1
ST-MoE-32B
92.4
-
Turing NLR v5
92.0
-
Vega v2
90.5
-
Ours (Educational purpose, training-based)
53.79
53.79
Ours (Educational purpose, llm-based)
97.47
97.47
Feel free to reach out if you encounter any issues or have questions regarding the implementation.
RTE Task Implementation (Training-based)
Overview
Recognizing Textual Entailment (RTE) is a task in NLP where the goal is to determine whether one piece of text (the hypothesis) can be inferred or logically deduced from another piece of text (the premise). In other words, given a premise sentence and a hypothesis sentence, the model needs to determine whether the premise entails, contradicts, or is neutral with respect to the hypothesis.
Source
Our implementation is based on the SuperGLUE dataset, a benchmark designed to evaluate the performance of natural language understanding models on diverse tasks.
For the most up-to-date information on the SuperGLUE dataset, you can visit the official website: SuperGLUE
Dataset and Source Code
You can download the dataset and source code using the following links:
Download the Dataset: Use the provided link to download the dataset.
Access Colab Notebook: Open the Colab notebook using the provided link. Make sure you have a Google account to access Colab.
Upload Dataset to Colab: If the dataset is not already included in the Colab environment, upload it using the appropriate commands.
Run Code Cells: Execute each code cell in the Colab notebook to go through the implementation steps.
Review Results: Check the output of the code cells to see the results of the task on the provided dataset.
Performance
This is a performance comparison table with state-of-the-art (SOTA) models.
The performance was measured using validation data, not a public benchmark test dataset. There may be slight differences in performance.
Model
Accuracy
F1
Vega v2
96.0
-
PaLM 540B
94.1
-
Turing NLR v5
94.1
-
Ours (Educational purpose, training-based)
53.79
53.79
Ours (Educational purpose, llm-based)
97.47
97.47
Feel free to reach out if you encounter any issues or have questions regarding the implementation.
WiC Task Implementation (LLM-based)
Overview
WiC (The Word-in-Context Dataset), as a benchmark for evaluating context-sensitive word embeddings, consists of a binary classification task that requires determining true or false.
Source
Our implementation is based on the SuperGLUE dataset, a benchmark designed to evaluate the performance of natural language understanding models on diverse tasks.
For the most up-to-date information on the SuperGLUE dataset, you can visit the official website: SuperGLUE
Dataset and Source Code
You can download the dataset and source code using the following links:
Download the Dataset: Use the provided link to download the dataset.
Access Colab Notebook: Open the Colab notebook using the provided link. Make sure you have a Google account to access Colab.
Upload Dataset to Colab: If the dataset is not already included in the Colab environment, upload it using the appropriate commands.
Run Code Cells: Execute each code cell in the Colab notebook to go through the implementation steps.
Review Results: Check the output of the code cells to see the results of the task on the provided dataset.
Performance
This is a performance comparison table with state-of-the-art (SOTA) models.
The performance was measured using validation data, not a public benchmark test dataset. There may be slight differences in performance.
Model
Accuracy
F1
ST-MoE-32B
77.4
-
Turing NLR v5
77.1
-
Vega v2
77.7
-
Ours (Educational purpose, trining-based)
68.2
68.2
Ours (Educational purpose, llm-based)
59.8
59.8
Feel free to reach out if you encounter any issues or have questions regarding the implementation.
WiC Task Implementation (Training-based)
Overview
WiC (The Word-in-Context Dataset), as a benchmark for evaluating context-sensitive word embeddings, consists of a binary classification task that requires determining true or false.
Source
Our implementation is based on the SuperGLUE dataset, a benchmark designed to evaluate the performance of natural language understanding models on diverse tasks.
For the most up-to-date information on the SuperGLUE dataset, you can visit the official website: SuperGLUE
Dataset and Source Code
You can download the dataset and source code using the following links:
Download the Dataset: Use the provided link to download the dataset.
Access Colab Notebook: Open the Colab notebook using the provided link. Make sure you have a Google account to access Colab.
Upload Dataset to Colab: If the dataset is not already included in the Colab environment, upload it using the appropriate commands.
Run Code Cells: Execute each code cell in the Colab notebook to go through the implementation steps.
Review Results: Check the output of the code cells to see the results of the task on the provided dataset.
Performance
This is a performance comparison table with state-of-the-art (SOTA) models.
The performance was measured using validation data, not a public benchmark test dataset. There may be slight differences in performance.
Model
Accuracy
F1
ST-MoE-32B
77.4
-
Turing NLR v5
77.1
-
Vega v2
77.7
-
Ours (Educational purpose, trining-based)
68.2
68.2
Ours (Educational purpose, llm-based)
59.8
59.8
Feel free to reach out if you encounter any issues or have questions regarding the implementation.
WikiHow Task Implementation (LLM-based)
Overview
WikiHow is a task that involves summarizing a passage to generate an overview.
Source
Our implementation is based on the WikiHow dataset, a benchmark designed to evaluate the performance of summarization tasks.
For the most up-to-date information on the WikiHow dataset, you can visit the official website: WikiHow
Dataset and Source Code
You can download the dataset and source code using the following links:
Download the Dataset: Use the provided link to download the dataset.
Access Colab Notebook: Open the Colab notebook using the provided link. Make sure you have a Google account to access Colab.
Upload Dataset to Colab: If the dataset is not already included in the Colab environment, upload it using the appropriate commands.
Run Code Cells: Execute each code cell in the Colab notebook to go through the implementation steps.
Review Results: Check the output of the code cells to see the results of the task on the provided dataset.
Performance
This is a performance comparison table with state-of-the-art (SOTA) models.
The performance was measured using validation data, not a public benchmark test dataset. There may be slight differences in performance.
Model
Rouge1
BertSum
35.9
MatchSum
31.8
Pointer-generator + coverage
28.5
Ours (Educatinal purpose, trining-based)
18.8
Ours (Educational purpose, llm-based)
16.5
Feel free to reach out if you encounter any issues or have questions regarding the implementation.
WikiHow Task Implementation (Training-based)
Overview
WikiHow is a task that involves summarizing a passage to generate an overview.
Source
Our implementation is based on the WikiHow dataset, a benchmark designed to evaluate the performance of summarization tasks.
For the most up-to-date information on the WikiHow dataset, you can visit the official website: WikiHow
Dataset and Source Code
You can download the dataset and source code using the following links:
Download the Dataset: Use the provided link to download the dataset.
Access Colab Notebook: Open the Colab notebook using the provided link. Make sure you have a Google account to access Colab.
Upload Dataset to Colab: If the dataset is not already included in the Colab environment, upload it using the appropriate commands.
Run Code Cells: Execute each code cell in the Colab notebook to go through the implementation steps.
Review Results: Check the output of the code cells to see the results of the task on the provided dataset.
Performance
This is a performance comparison table with state-of-the-art (SOTA) models.
The performance was measured using validation data, not a public benchmark test dataset. There may be slight differences in performance.
Model
Rouge1
BertSum
35.9
MatchSum
31.8
Pointer-generator + coverage
28.5
Ours (Educatinal purpose, trining-based)
18.8
Ours (Educational purpose, llm-based)
16.5
Feel free to reach out if you encounter any issues or have questions regarding the implementation.